
Multi Modal Large Language Models - 1- Introduction
Focused on Open Source Large Language Vision Models.

Recently, we've seen ChatGPT-4 and Gemini performing impressive feats with image inputs. Remember the Gemini duck video, where the model answered questions based on hand drawings and gestures? If you found this 'wow!'-worthy and are curious about the underlying technology, then this blog is for you.
Multimodal Large Language Models (MLLMs) are behind the impressive feats done by GPT-4 and Gemini. "Multimodal" simply means accepting more than one type of input for the model. You can provide text, images, audio, or videos, and the model delivers a response based on that information. For this article, let's focus on the powerful combination of images and text, also known as Large Language Vision Models (LLVMs).
I began working with LLVM in July 2023. Back then, only a handful of multimodal models like Instruct Blip, Kosmos-2, and Flamingo existed, and to be honest, their performance was underwhelming. Moreover, with the exception of Kosmos-2 and Instruct Blip, these models were neither truly open-source nor available for commercial use. However, the past 3-4 months have witnessed an exponential growth in the field, bringing us powerful models like Qwen-VL, CogVLM, LLaVA, GPT-4, and Gemini. This article will provide an introduction to some of the open-source LLVM models, explore the current state of LLVM, and speculate on its future, drawing primarily from my personal experience.

{kind=link}
The Models we are going to explore are:
Qwen-VL
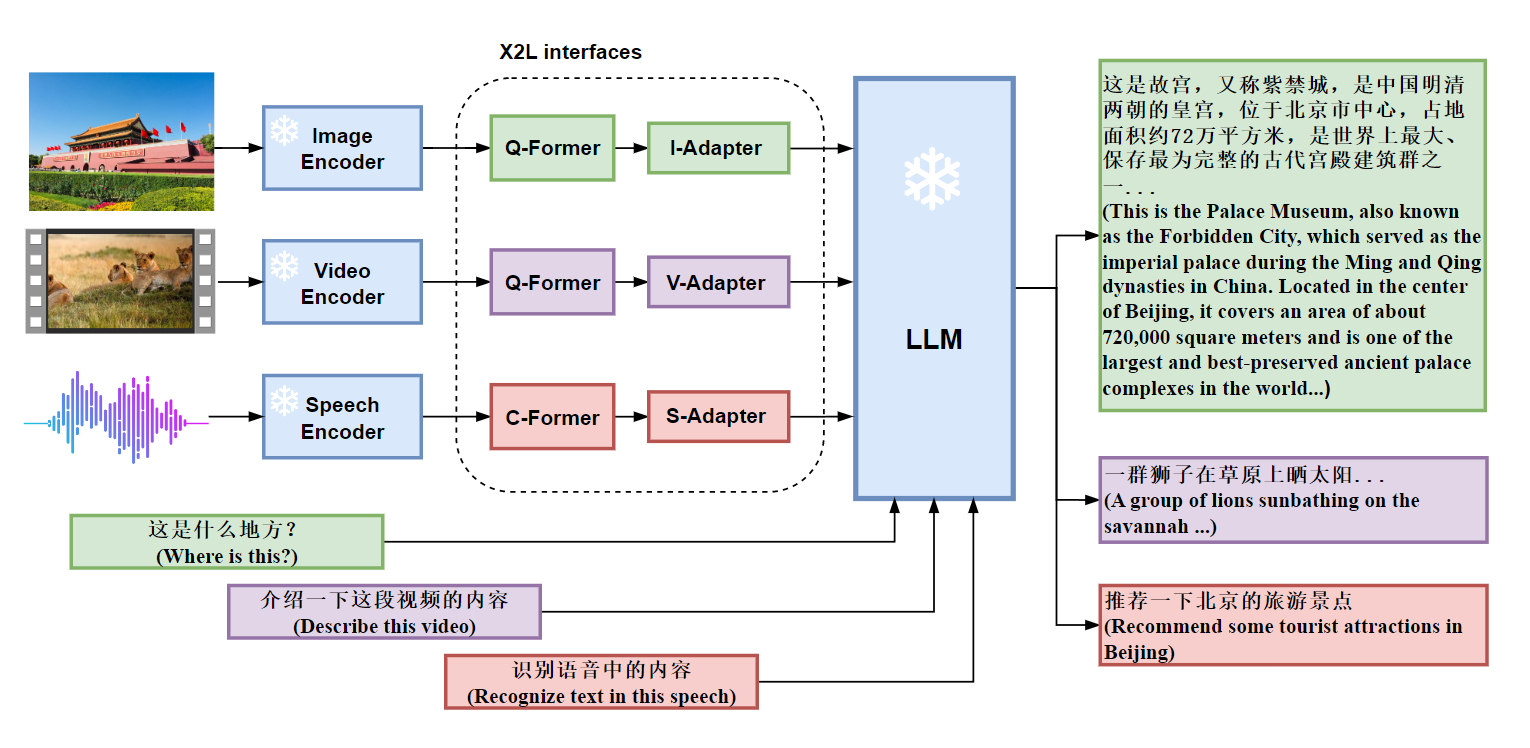
Qwen-VL (Qwen Large Vision Language Model) is the multimodal version of the large model series, Qwen (abbr. Tongyi Qianwen), proposed by Alibaba Cloud. Qwen-VL accepts image, text, and bounding box as inputs, outputs text and bounding box.
When it was released, it was the best-performing model on all benchmarks, and its results were truly mind-blowing. It was also the first model to accept 448x448 resolution images, while others were accepting 224x224.
{kind=link}
It has 2 versions:
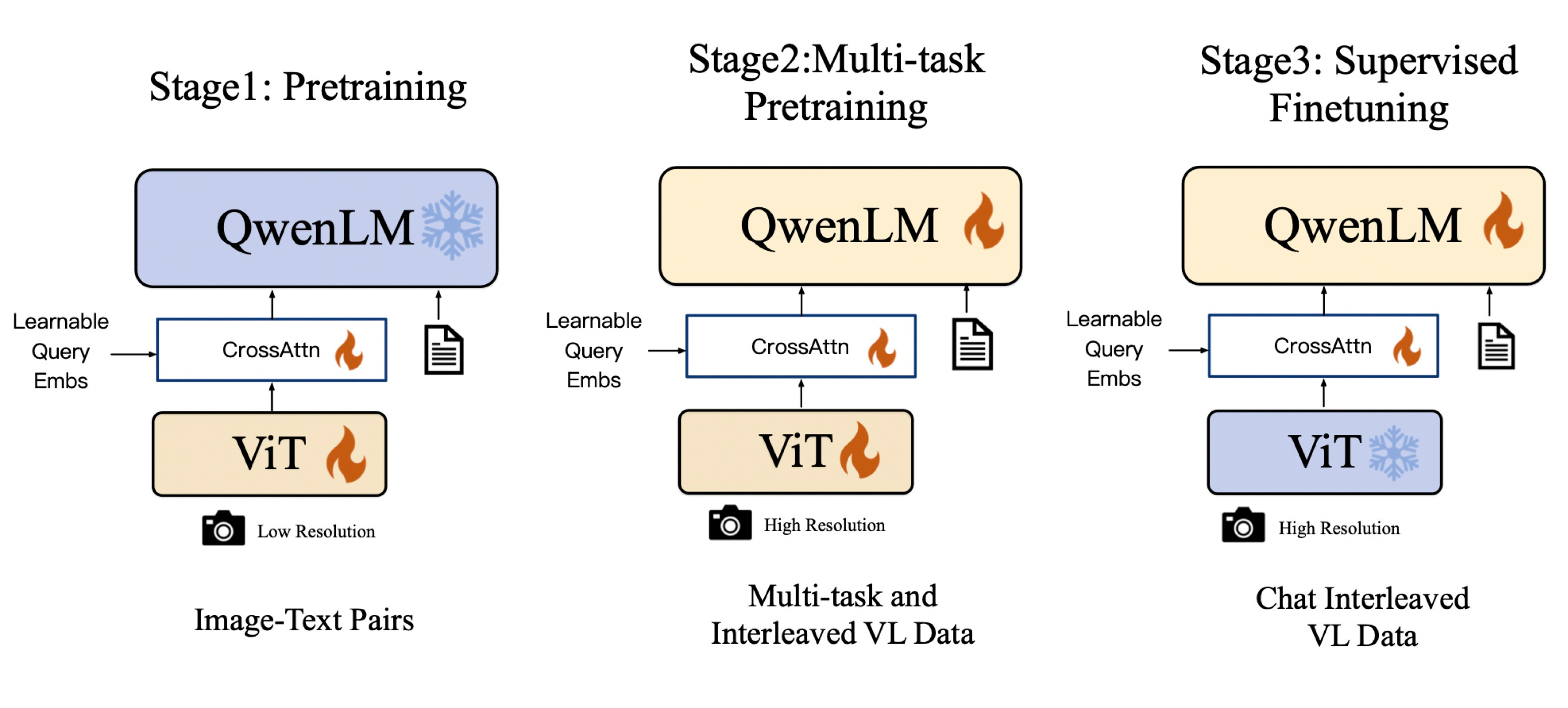
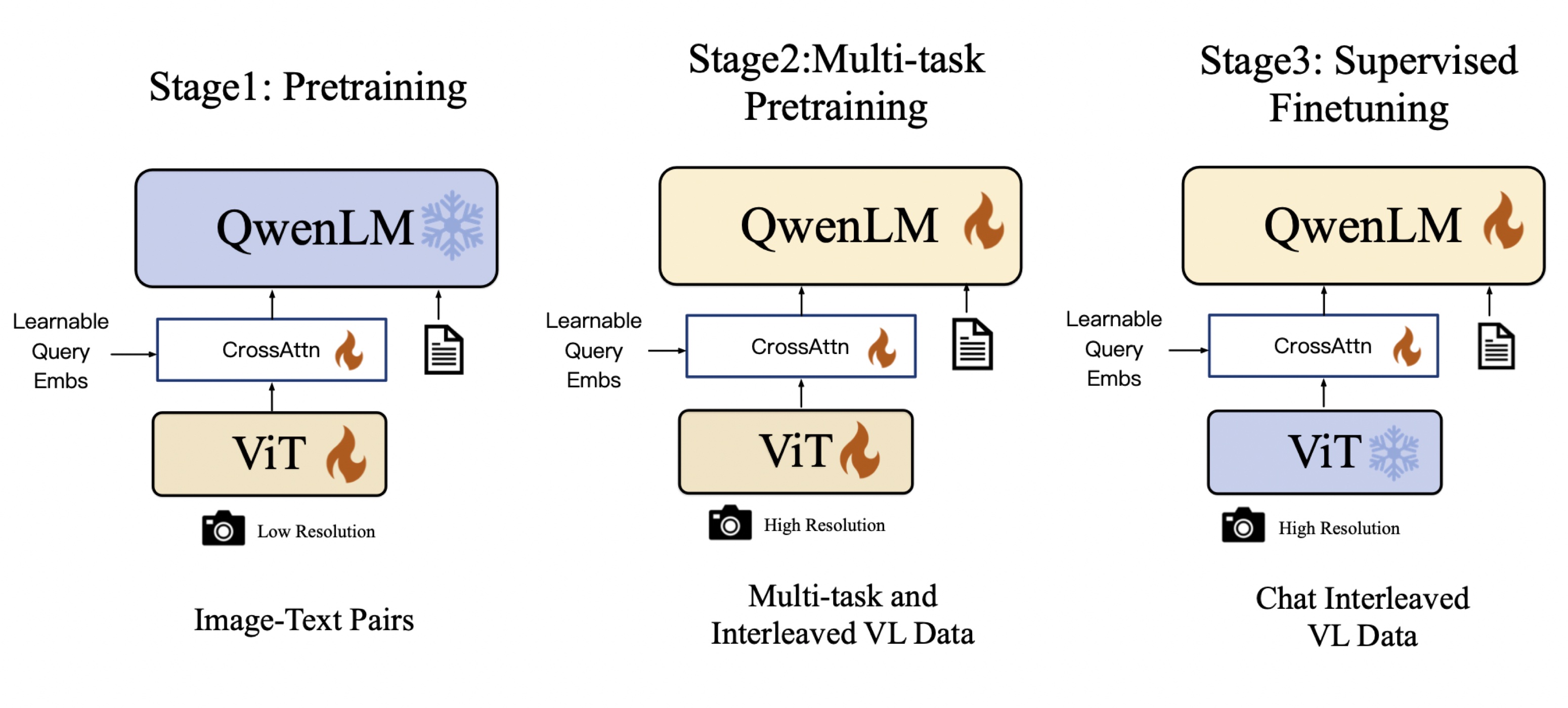
Qwen-VL: The pre-trained LVLM model uses Qwen-7B as the initialization of the LLM, and Openclip ViT-bigG as the initialization of the visual encoder. And connects them with a randomly initialized cross-attention layer.
Qwen-VL-Chat: A multimodal LLM-based AI assistant, which is trained with alignment techniques. Qwen-VL-Chat supports more flexible interaction, such as multiple image inputs, multi-round question answering, and creative capabilities. This is the model to go for your experiments.
Recently, they also released a new version called Qwen-VL-Plus, which they claim beats ChatGPT-4 and GeminiPro in several benchmarks.

{kind=link}
Advantages:
Its commercial availability makes it an attractive option for organizations to use for various applications.
Strong performance: It significantly surpasses existing open-sourced LLVM under similar model scale on multiple English evaluation benchmarks (including Zero-shot Captioning, VQA, DocVQA, and Grounding).
Multi-lingual LLVM supporting text recognition: Qwen-VL naturally supports English, Chinese, and multi-lingual conversation, and it promotes end-to-end recognition of Chinese and English bi-lingual text in images.
Multi-image interleaved conversations: This feature allows for the input and comparison of multiple images, as well as the ability to specify questions related to the images and engage in multi-image storytelling.
First generalist model supporting grounding in Chinese: Detecting bounding boxes through open-domain language expression in both Chinese and English.
Fine-grained recognition and understanding: Compared to the 224*224 resolution currently used by other open-sourced LLVM, the 448*448 resolution promotes fine-grained text recognition, document QA, and bounding box annotation.
Disadvantages:
Stability concerns: Highly unreliable; they once removed model weights and everything from Hugging Face and went offline for weeks. This raises questions about long-term reliability and access.
Limited openness: Despite being labeled as 'open-sourced,' significant portions of the model and its tools remain closed-source, hindering user customization and community-driven improvements.
Hallucination: Even though it performs decently in many domains, hallucination still exists, especially in high-stakes domains like healthcare.
While Qwen-VL may excel in certain areas, our experience with fine-tuning it for health data suggests it might not perform well with all types of data or tasks. Again, this can be subjective and depends on factors such as the amount of data we are using and data quality.
check here for more: https://github.com/QwenLM/Qwen-VL/tree/master
LLaVA: Large Language and Vision Assistant
LLaVA is an end-to-end trained large multimodal model that connects a vision encoder and LLM for general-purpose visual and language understanding. LLaVA is developed by Microsft. An important thing to note here is that LLaVA is trained on Chatgpt generated data.
Recently LLaVA-1.5 is released and it achieves SoTA(State of the art) on 11 benchmarks, with just simple modifications to the original LLaVA, utilises all public data, completes training in ~1 day on a single 8-A100 node, and surpasses methods that use billion-scale data.

Advantages:
Better Performance: Their early experiments showed that LLaVA demonstrates impressive multimodal chat abilities, sometimes exhibiting the behaviours of multimodal GPT-4 on unseen images/instructions, and yields an 85.1% relative score compared with GPT-4 on a synthetic multimodal instruction-following dataset. When fine-tuned on Science QA, the synergy of LLaVA and GPT-4 achieves a new state-of-the-art accuracy of 92.53%.
Continuous Innovation: There’s something new coming from their team every week. A lot of other models such as Vip-LLaVA, SharegptGPT-4V etc. are also recently developed using LLaVA as their base.
Disadvantages:
Not available for commercial use. And to be honest, do not trust any model coming out of Microsoft for commercial use; they can change the license any day. This will put your team in jeopardy once the model is deployed to production.
LLaVA's reliance on ChatGPT generated train data introduces the potential for biases and inaccuracies to be embedded within the model. This can result in outputs that are unreliable, misleading, or even "hallucinatory," potentially undermining its trustworthiness in critical applications.
check here for more: https://llava-vl.github.io/
online demo: https://llava.hliu.cc/
CogVLM
CogVLM is a powerful, fully open-sourced LLVM. CogVLM-17B possesses 10 billion vision parameters and 7 billion language parameters. The same team also recently released CogAgent-18B, boasting 11 billion visual parameters and 7 billion language parameters, along with GUI image agent capabilities akin to GPT-4.

Advantages:
Currently the best fully open-sourced model for commercial use. CogVLM-17B achieves state-of-the-art performance on 10 classic cross-modal benchmarks, including NoCaps, Flicker30k captioning, RefCOCO, RefCOCO+, RefCOCOg, Visual7W, GQA, ScienceQA, VizWiz VQA, and TDIUC. It ranks 2nd on VQAv2, OKVQA, TextVQA, COCO captioning, etc., surpassing or matching PaLI-X 55B.
Reduced hallucination compared to other models.
Accepts high-resolution images of 490*490. CogAgent can even support image understanding at a resolution of 1120*1120.
Disadvantages:
Requires significant GPU resources. Inference alone demands at least 2*24GB GPUs or 1*80GB GPU. Fine-tuning is challenging due to its high GPU demands.
check here for more: https://github.com/THUDM/CogVLM
online demo: http://36.103.203.44:7861/

{kind=link}
Kosmos-2
Kosmos-2, the second installment in Microsoft's UNLIM series, holds a significant place in the history of MLLM development as one of the early open-sourced models. However, its performance and usability haven't always matched expectations. Initially, the model was notoriously difficult to run and perform inference on, requiring users to manually set up the entire ecosystem. Thankfully, the recent introduction of a Hugging Face implementation has eased some of these challenges.
Microsoft recently released Kosmos-2.5, though it's not open-sourced. You can find more details in the research paper here: https://arxiv.org/abs/2309.11419

{kind=link}
Advantages:
None, to be honest; that’s probably why Microsoft made this model fully open source compared to other models.
Disadvantages:
Performance on Complex Images: Kosmos-2 struggles with images beyond basic complexity, especially in sensitive domains like healthcare. It tends to generate unreliable outputs or 'hallucinate,' limiting its real-world applicability. In my experience dealing with multimodal LLMs, this model has the highest hallucination.
check here for more: https://github.com/microsoft/unilm/tree/master/kosmos-2
online demo: https://huggingface.co/spaces/ydshieh/Kosmos-2
Instructblip
InstructBlip, from Salesforce's LAVIS team, was a landmark contribution to the open-source community. It was the first model to truly showcase the potential of multimodality, as evidenced by the amazement surrounding its early captioning, like "a man in a yellow shirt ironing in the backseat of a car on a busy New York street." Though not the top performer by today's standards, it remains a capable multimodal model that deserves recognition for its early impact.
{kind=link}
Recently they have released X-InstructBLIP, which demonstrates joint reasoning abilities on par with models specifically trained on combined-modality datasets, such as video-audio. check out more in the below link https://github.com/salesforce/LAVIS/tree/main/projects/xinstructblip
Advantages:
Hugging Face implementation makes InstructBlip straightforward to run.
InstructBlip's partial open-source license unlocks some commercial use cases, making it a viable option for diverse applications.
Disadvantages:
Despite decent overall performance, InstructBlip's results on various benchmarks fall short of current standards, suggesting potential limitations in demanding tasks compared to newer models.
The potentially superior Blip + Vicuna version remains commercially unavailable, leaving users with the Blip + flan-t5 combination, which may face constraints due to flan-t5's known weaknesses in language generation capabilities.
check here for more: https://github.com/salesforce/LAVIS/tree/main/projects/instructblip
Honorable Mentions:
BakLLaVA:
BakLLaVA merges a Mistral 7B base with the LLaVA 1.5 architecture for enhanced multimodal capabilities.
Initial findings reveal that this model outperforms the Llama-2 13B on several benchmarks, suggesting promising potential.
check here more: https://github.com/SkunkworksAI/BakLLaVA
Flamingo
Open Flamingo, released by Google DeepMind, serves as a foundational model for diverse multimodal advancements.
Its versatility has spawned numerous Flamingo-based models, including Instruct Flamingo and Med-Flamingo, demonstrating its widespread influence.
check here more: https://github.com/mlfoundations/open_flamingo
mPLUG-Owl
mPLUG-Owl stands as an another exciting multimodal LLM from Alibaba, equipped with video input processing capabilities, expanding its scope of understanding.
The recently released mPLUG-Owl-2 builds upon its predecessor's strengths, offering further enhancements and performance improvements.
check here more: https://github.com/X-PLUG/mPLUG-Owl
Future of Multi Modal LLMs
I predict a surge in the near future of domain-specific Multi-modal LLMs (MLLMs) catering to healthcare, finance, and other sectors. The key lies in fine-tuning or building these models with your own data for specific use cases. Smaller, specialized models offer several advantages, including reduced hallucination, easier productionization, cost savings, and greater control over the model and its development process.
I also expect to see better evaluation strategies for MLLMs. Metrics like BLEU, ROUGE, and CIDEr are insufficient, and manual evaluation can be costly and time-consuming. I believe this process will evolve towards more robust and efficient methods.
Finally, further research in hallucination mitigation and visual prompting techniques is crucial. Hallucination is one of the biggest challenges facing MLLMs, and currently, there are limited resources and ineffective techniques like woodpecker and Set of Mark prompting. I'm excited to see what the future holds for this area of research.
set of mark prompting: https://github.com/microsoft/SoM
Woodpecker: https://github.com/BradyFU/Woodpecker
Summary Table:

Conclusion:
The past six months have witnessed stunning advancements and groundbreaking achievements in the world of multi-modal large language models. This exciting momentum is poised to continue in the coming year, with the open-source community playing a crucial role in driving further progress. Stay tuned for an even more captivating future!.
More Resources:
https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models/tree/Evaluation
https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models