
Accelerating Data Processing: How OpenAI’s Asynchronous API and Concurrent PDF Processing Enhance Speed and Scalability
Exploring the Impact of OpenAI’s Async API and Asynchronous File Handling on Data Extraction Efficiency and Scalability

Table of Content
Introduction
As data volumes continue to grow, the demand for faster and more efficient processing becomes increasingly important. Whether extracting information from PDFs or handling numerous API calls, traditional synchronous methods can lead to slower execution times and inefficient use of resources.
Recently, I encountered a challenge while processing PDFs and making multiple API requests for entity extraction. A purely synchronous approach would have caused significant delays, especially when handling a large number of documents and requests. To tackle this, I turned to asynchronous programming.
In this blog, I'll walk you through how I optimized the process using asynchronous functionality for both API calls and PDF processing. Please note that certain code snippets and details have been omitted to maintain confidentiality, as this is part of an ongoing project.
Introduction to Asynchronous Programming
Before diving into the implementation and optimizations, it's important to grasp the concept of asynchronous programming. Unlike traditional synchronous programming, where tasks are executed sequentially (with each task blocking the next until it completes), asynchronous programming enables tasks to run independently. This non-blocking behavior is especially effective for I/O-bound tasks like file reading, API calls, and database queries.
In Python, we achieve asynchronous programming using asyncio, which allows us to write concurrent code. When you make API requests or read files asynchronously, the code doesn't stop while waiting for the server to respond or for the file to load. Instead, it continues executing other tasks in parallel, significantly improving performance.
I highly recommend watching the two videos mentioned in the References Section to familiarize yourself with asynchronous programming. While not required to understand this article, they offer a deeper dive into the topic if you're interested.
The Workflow: API Calls and PDF Processing
The workflow for extracting entities from PDFs and sending them to an API is split into several steps:
Asynchronous PDF Processing with Threads: Extracting relevant text using PyMuPDF.
Prompt Generation: Creating prompts for entity extraction from the text.
Asynchronous API Calls: Sending prompts concurrently to an API.
Handling API Responses and Retry Mechanism: Processing the API responses to extract entities.
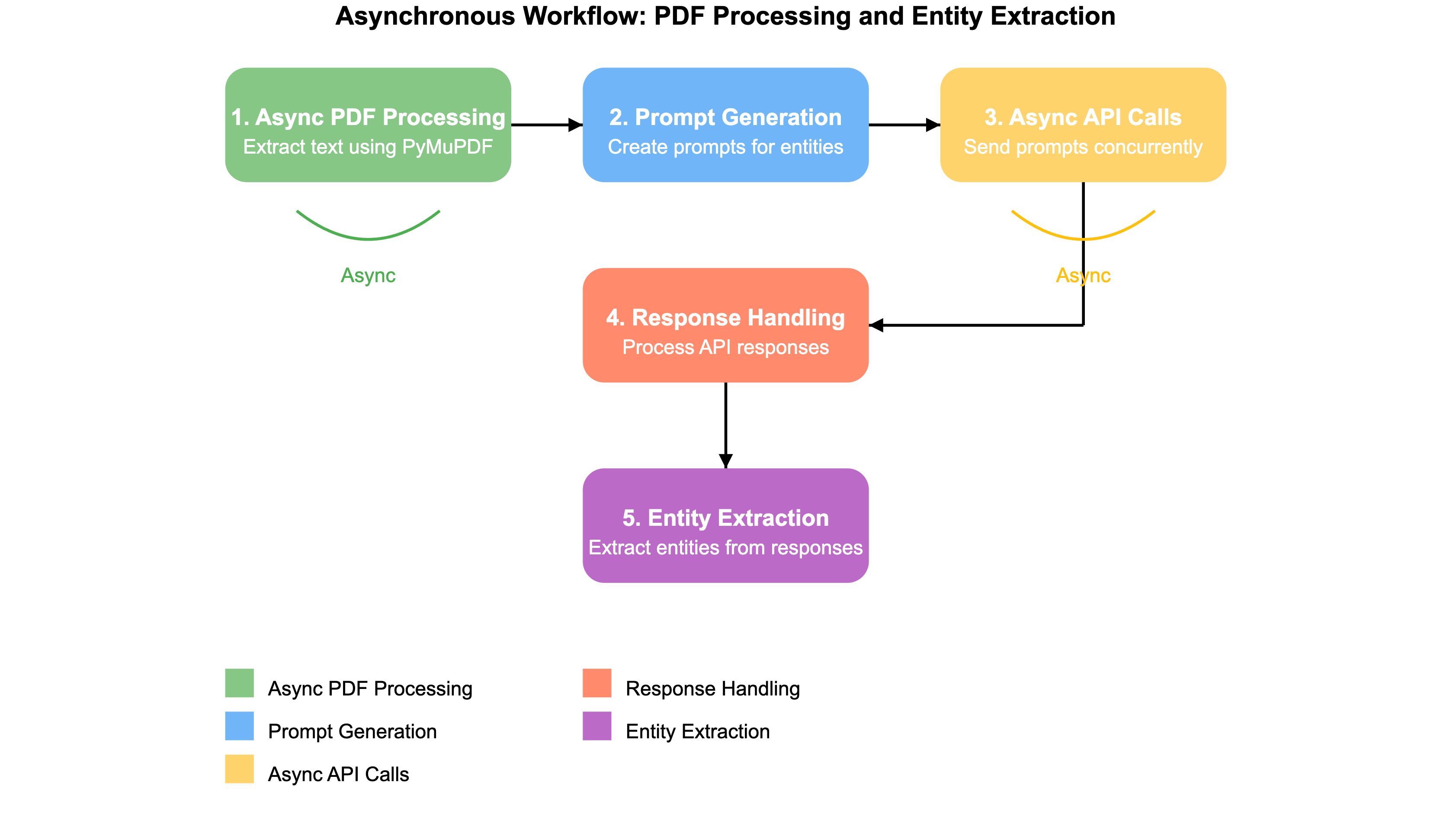
Breaking Down the Workflow
1. Asynchronous PDF Processing with Threads
I used PyMuPDF (fitz), a powerful library for reading and processing PDF files. For this project, the task involved extracting text from specific sections of the PDFs, such as the first few pages and the last few pages.
Here's the initial synchronous code used for extracting PDF text:
import fitz # PyMuPDF
def sync_get_pdf_text(pdf_path, pages):
doc = fitz.open(pdf_path)
if pages == "first":
return doc[0].get_text()
elif pages == "first_two_last_two":
if len(doc) <= 4:
return "\n\n".join([doc[ind].get_text() for ind in range(len(doc))])
else:
return "\n\n".join([doc[0].get_text(), doc[1].get_text(), doc[-2].get_text(), doc[-1].get_text()])
While this works well for small PDFs, processing larger files synchronously can block other operations, leading to delays. To improve efficiency, I offloaded the text extraction to a separate thread using Python's asyncio.to_thread() function. This allows the synchronous function to run in a separate thread while freeing up the main event loop to perform other tasks concurrently.
Here’s the asynchronous version:
async def get_pdf_text(pdf_path, pages):
# Offload the sync function to a separate thread for non-blocking
execution
return await asyncio.to_thread(sync_get_pdf_text, pdf_path, pages)
2. Generating Prompts
After extracting the text from the PDF, the next step is to generate prompts for entity extraction. These prompts instruct the API to extract specific entities from the text, such as Entity1 (E1), Entity2 (E2), and Entity3 (E3). For confidentiality reasons, I’m omitting the exact entities and prompts used in this project.
While the prompt generation itself is typically a quick operation that doesn't require asynchronous processing, it's worth noting that in more complex scenarios, you might want to consider making this step asynchronous as well, especially if it involves any I/O operations or complex computations.
The prompting technique I’m trying is called Prompt Chaining. If you want to know more about it, there’s a link to the article below in the Resources section. Prompt chaining is particularly helpful when you want to scale the number of entities.
Here's a simple example of how prompt generation might look:
def generate_prompt(pdf_text, entity_type):
# Create a prompt instructing the extraction of a specific entity
return f"Extract {entity_type} from the following text:\n\n{pdf_text}"
def generate_prompts(pdf_text):
# Generate prompts for multiple entities
return [
generate_prompt(pdf_text, "Entity1"),
generate_prompt(pdf_text, "Entity2"),
generate_prompt(pdf_text, "Entity3")
]
3. Asynchronous API Calls
When interacting with external APIs, synchronous calls can lead to inefficiencies, particularly when processing multiple requests. By using asynchronous programming, we can maintain application responsiveness while handling multiple requests concurrently.
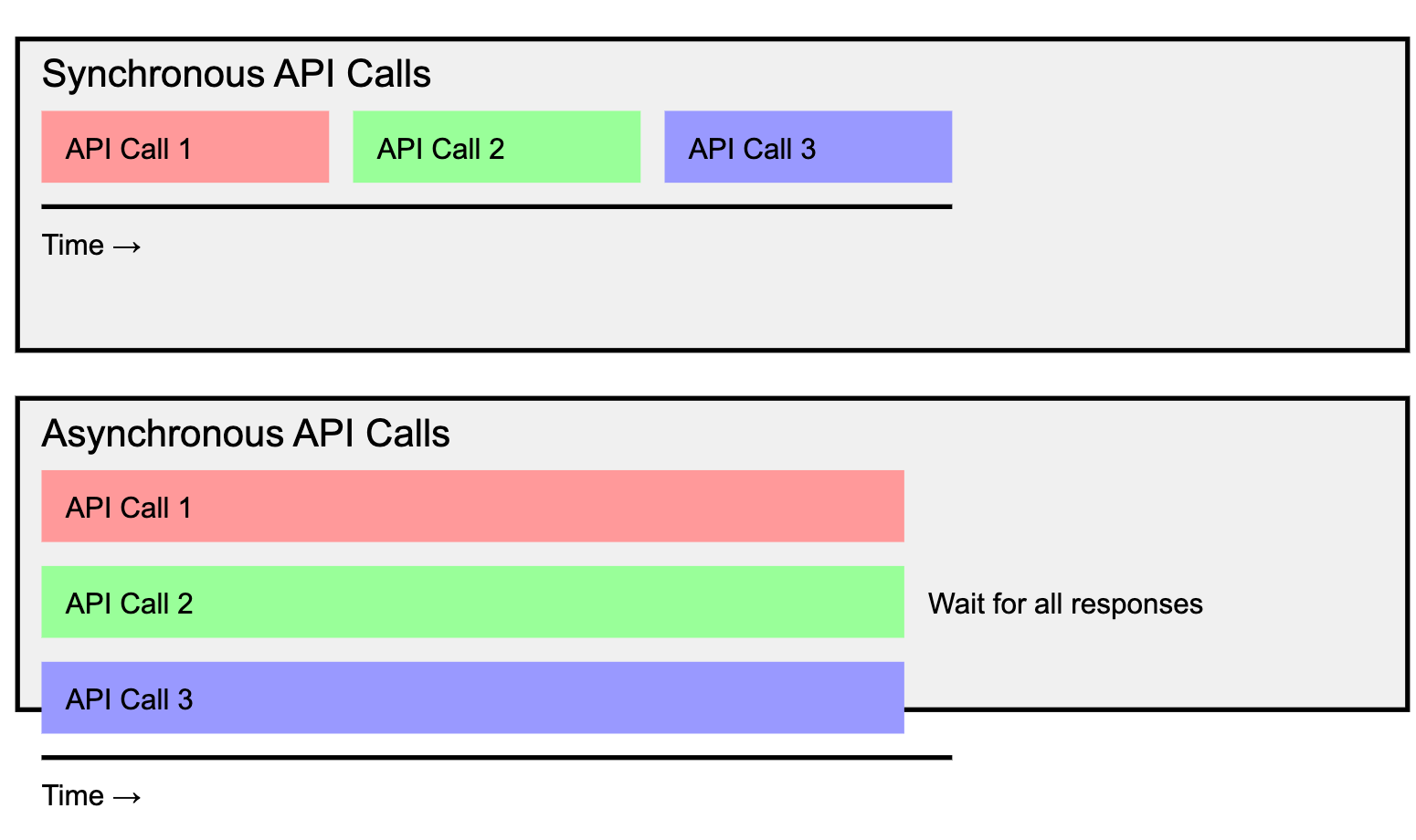
3.1 Synchronous vs. Asynchronous API Calls
Synchronous API Calls:
In a synchronous approach, each API call is made sequentially. The application waits for the response of each call before proceeding to the next one. This can lead to increased latency, as each request is dependent on the completion of the previous request.
Time:
|--- Request 1 --- Wait for Response 1 --- Request 2 --- Wait for
| Response 2 --- Request 3 --- Wait for Response 3
|_______________________________________________________________________
Asynchronous API Calls:
In an asynchronous approach, all API requests are initiated concurrently. The application does not wait for one request to finish before starting another. This allows handling multiple requests simultaneously, significantly reducing overall processing time.
Time:
|--- Request 1 ----------|
|--- Request 2 ----------|
|--- Request 3 ----------|
| Wait for All Responses
| Response 1 Response 2 Response 3
|_______________________________________________________________________
3.2 Implementing an Asynchronous API Client
For making asynchronous API calls, I used the AsyncAzureOpenAI client, which is designed to handle non-blocking requests to Azure’s OpenAI models. Here’s a detailed look at how this client is initialized and used:
Client Initialization:
The AzureAsyncClient class is initialized with configuration parameters such as API key, API version, and endpoint. This setup allows the client to interact with the OpenAI service asynchronously.
Instead of AsyncAzureOpenAI, you can use a similar OpenAI API functionality if you’re using the OpenAI API.
import json
from openai import AsyncAzureOpenAI
class AzureAsyncClient:
def __init__(self, config):
self.client = AsyncAzureOpenAI(
api_key=config["api_key"],
api_version=config["api_version"],
azure_endpoint=config["api_endpoint"]
)Making Asynchronous API Calls:
The get_completion method sends a prompt to the OpenAI model and awaits the response. The await keyword ensures that the call is non-blocking, allowing other tasks to proceed while waiting for the response.
async def get_completion(self, prompt):
try:
response = await self.client.completions.create(
model=config["model"],
messages=prompt,
temperature=0,
top_p=0
)
return json.loads(response.choices[0].message.content)
except Exception as e:
print(f"Error during API call: {e}")
return None
3.3 Handling Multiple Prompts Concurrently
Once the PDF text has been extracted, multiple prompts for entity extraction are generated. Instead of sending API requests one by one, asynchronous tasks are created for each request and run concurrently using asyncio.gather().
It’s important to ensure the correct order when dealing with dependent prompts. If the prompts rely on the output of a previous task, you’ll need to manage that sequence carefully.
Here’s an example of how prompts are processed asynchronously:
async def process_pdf_and_call_api(pdf_text):
client = AzureAsyncClient(config)
prompts = [
generate_prompt(pdf_text, "Entity1"),
generate_prompt(pdf_text, "Entity2"),
generate_prompt(pdf_text, "Entity3")
]
tasks = [client.get_completion(prompt) for prompt in prompts]
responses = await asyncio.gather(*tasks)
return responses
Key Points:
Asynchronous Tasks: For each prompt, we create an asynchronous task using the
get_completionfunction, which sends a request to the API to process that specific prompt. These tasks are created as soon as we have our list of prompts, but they aren’t yet executed.asyncio.gather(*tasks): This function runs all the tasks concurrently. It allows you to run multiple asynchronous operations in parallel and collect their results when they all finish. Each task runs independently, so while the first API request is waiting for a response, the second and third API requests are already being made, saving time.
3.4 Performance Comparison
Sequential Requests:
async def process_sequential(pdf_text):
client = AzureAsyncClient(config)
prompt1_response = await client.get_completion(generate_prompt(pdf_text, "Entity1"))
prompt2_response = await client.get_completion(generate_prompt(pdf_text, "Entity2"))
prompt3_response = await client.get_completion(generate_prompt(pdf_text, "Entity1"))
return [prompt1_response, prompt2_response, prompt3_response]
Here, each API request is made one after the other. If each request takes 2 seconds, the total time for all three requests would be 6 seconds.
Total time: 2 seconds + 2 seconds + 2 seconds = 6 seconds
Concurrent Requests:
async def process_pdf_and_call_api(pdf_text):
client = AzureAsyncClient(config)
prompts = [
generate_prompt(pdf_text, E1_prompt),
generate_prompt(pdf_text, E2_prompt),
generate_prompt(pdf_text, E3_prompt)
]
tasks = [client.get_completion(prompt) for prompt in prompts]
responses = await asyncio.gather(*tasks)
return responses
All three API requests run in parallel, reducing the total time to about the time of the longest request—so, if each request takes 2 seconds, the total time for all three requests would be around 2 seconds instead of 6.
Total time: Approximately 2 seconds (the time of the longest request)
This demonstrates a potential 66% reduction in processing time for just three API calls. The benefits become even more pronounced as the number of API calls increases.
Real-World Performance Gains:
In our experiments, we noticed a significant increase in speed when extracting entities from PDFs using asynchronous API calls. This process included both text extraction from PDFs and entity extraction via APIs.
Best Case Scenario:
20 Samples: Up to 4x faster
10 Samples: Up to 6x faster
Worst Case Scenario:
20 Samples: Approximately 1.2x faster
10 Samples: Up to 6.4x faster
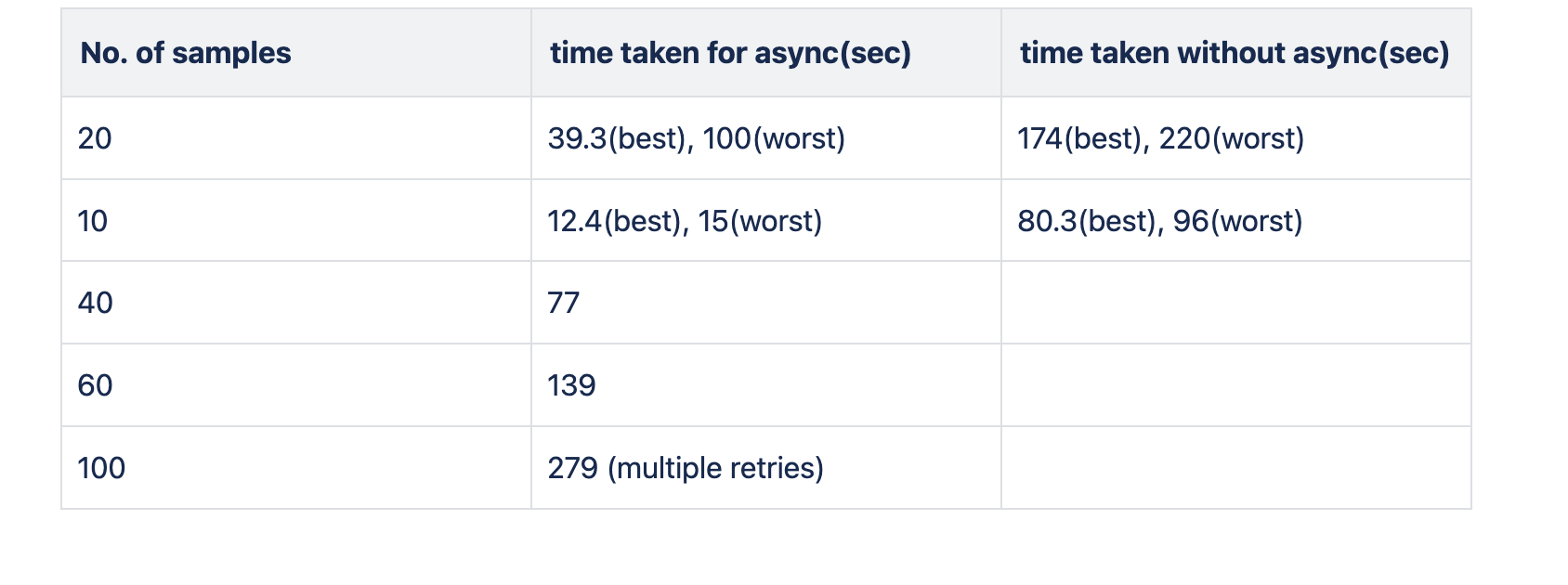
Above is a summary of the benchmark results, where the "Best" time represents the fastest extraction time recorded in multiple tests, and the "Worst" time represents the slowest. Benchmarking was halted as the number of PDFs increased due to cost and time constraints. However, the results clearly indicate that asynchronous functionality can provide a 2-3x increase in processing speed in typical scenarios.
4. Handling API Responses and Retry Mechanism
After receiving API responses, the next step is to process them to extract relevant entities. It's also essential to implement a retry mechanism to handle potential API failures, such as rate limit issues.
4.1 Retry Mechanism
When working with asynchronous API calls, it's common to encounter rate limits, often resulting in 429 errors. To handle these errors gracefully, a retry mechanism with an exponential backoff strategy is crucial.
Here’s a simplified implementation of the retry strategy:
import random
async def get_completion_with_retries(client, prompt, max_retries=5):
retries = 0
while retries < max_retries:
try:
response = await client.get_completion(prompt)
return response
except Exception as e:
if retries < max_retries:
wait_time = (2 ** retries) + random.uniform(0, 1)
print(f"Retrying in {wait_time:.2f} seconds...")
await asyncio.sleep(wait_time)
retries += 1
else:
raise
Key Points of the Retry Mechanism:
Max Retries: The process will retry up to a specified number of times (e.g., 5) before giving up. This prevents infinite retry loops.
Exponential Backoff: The wait time between retries increases exponentially, reducing the likelihood of immediately overloading the API with retries.
Rate-Limiting Awareness: The retry logic is designed to handle rate-limit-related errors effectively.
4.2 Alternative Solutions
While implementing your own retry logic is straightforward and customizable, you can also use libraries like Tenacity or Backoff to simplify the process. However, I prefer to avoid additional libraries due to the extra maintenance they require and potential complexity they introduce.
For further reading, refer to the https://platform.openai.com/docs/guides/rate-limits on handling rate limits and retries.
Conclusion
By employing asynchronous programming, I have significantly optimized the process of extracting entities from PDFs and managing API requests. The main advantages include:
Non-Blocking Operations: Asynchronous functions handle I/O-bound tasks without blocking, improving overall resource utilization and application responsiveness.
Concurrency with
asyncio.gather(): Concurrently managing multiple API requests reduces overall execution time, leading to faster processing.Scalability: This approach is highly scalable, efficiently handling large volumes of data and numerous prompts.
Asynchronous programming has proven to be transformative for workflows involving I/O-heavy operations like API calls and PDF processing. The techniques discussed are applicable to a variety of projects that demand swift and efficient data extraction.
References
Python Async Tutorial Vidoes:
Prompt Chaining: https://www.datacamp.com/tutorial/prompt-chaining-llm